



UNDERSTANDING THE PROBLEM
Data science is really an infinite road! After getting a good feel by solving a few problem statement and getting a decent accuracy, I wanted to deep dive into the field and know more on how I could improve my accuracy. Realizing the importance of variance and correlation was a good learning. In TFI Restaurant Revenue Prediction problem, I was surprised to get a rank of 6, but unfortunately, the competition wasn’t an active one.
Kaggle link: Restaurant Revenue Prediction
Problem Statement:
To predict the annual revenue of restaurants using the revenue of similar restaurants.
Luckily the problem statement is simple here and data is pretty nicely explained.
The data:
The first thing which is surprising here is the low data points in the training set compared to the test set. Using only 137 data points we need to predict for 1 lac points. Opening Date, Type of the restaurant, City, City groups and 37 demographical features.
Initial Observation
- There are no missing data. (Whooo!)
- The City name in the test and train do not match, hence would need to do some feature engineering or ignore these
- The demographic features, P1 to P37 can have high correlation
- We need to predict a continuous variable using factors and numeric values, so checking if there is are outliers in the response variable would be a good option. (Box plot can be used (check Visualization tab), and if there are outliers then we can take log of the revenue or ignore extreme values)
Feature Engineering
- Firstly, the most obvious thing to do here would be to split the date and time. Make new variables for month, year, date.
- With a max date substract the openning date. How old a restaurant is, could give a good insight about the annual revenue.
- Can try using PCA for the 37 demographaic variables
- For Cities, the grouping is already done according to the size. Using data(world.cities) from the package maps you could use the latitude-longitude or even population.
Now let us visualize the data as much as possible and then try to develop a model to predict.
EXPLORATORY DATA ANALYTICS
Now, let’s visualize the data for TFI Restaurant Revenue Prediction we have and see if it really makes any sense and if we can get some more insight.
- As previously mentioned, let us draw the boxplot for ‘count’ to check for outliers.
Since there are a few outliers, let us ignore the restaurants with revenue greater than 16000000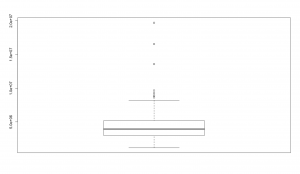
- The 37 demographic feature and the histogram plot for each of them

- We have introduced another feature of how long ago (in months) the restaurant was launched. Let’s see if we get a good relation with revenue
- Using random forests we can see the relative importance of various parameters in the initially given data and then build new feature accordingly.
The plot shows how important is the date of this prediction and we can even understand that intuitively.
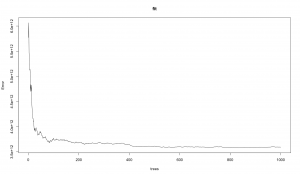
The next graph shows the error vs the number of trees (estimators) used in the random forest.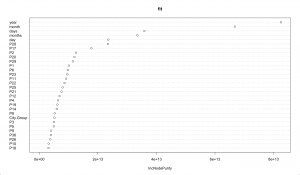





PREDICTING REVENUE
Code for Rank 6 in Kaggle TFI Restaurant Revenue Prediction. Here we have factors as well as numeric variables in this prediction and we have to predict continuous variable. Had tried regression on this, which is the first method which comes in mind when it comes to predicting continuous values, but that did not work well. So here is the code using the random forest in R. It was totally unexpected to get such a rank with not much time spent on it.
# Author: Himanshu Sikaria # Title : Kaggle TFI Restaurant Revenue Prediction tutorial # Model: Random Forest library(randomForest) require(party) library(dplyr) library(reshape) # Reading the data train <- read.csv("~/Downloads/train.csv") test <- read.csv("~/Downloads/test.csv") # Removing outliers train <- train[train$revenue < 16000000,] # Combining train and test target = train$revenue train_row = nrow(train) train$revenue <- NULL full = rbind(train, test) # Plotting histogram for P1 to P37 d <- melt(train[,-c(1:5)]) ggplot(d,aes(x = value)) + facet_wrap(~variable,scales = "free_x") + geom_histogram() # Spliting date full$year <- substr(as.character(full$Open.Date),7,10) %>% as.factor() full$month <- substr(as.character(full$Open.Date),1,2) %>% as.factor() full$day <- substr(as.character(full$Open.Date),4,5) %>% as.numeric() full$Date <- as.Date(strptime(full$Open.Date, "%m/%d/%Y")) # How old the restaurant is full$days <- as.numeric(as.Date("2014-02-02")-full$Date) full$months <- as.numeric(as.Date("2014-02-02")-full$Date) / 30 qplot(revenue, month, data=train) + geom_smooth() + ggtitle("Life of restaurant (months) vs Revenue") # Removing columns which are not to be used full$Id <- full$Open.Date <- full$Date <- full$City <- NULL # Spliting into train and test train = full[1:train_row,] train$revenue = target test = full[(train_row+1):nrow(full),] row.names(test) = NULL # Random Forest set.seed(147) fit = randomForest(revenue~., train, ntree = 1000) varImpPlot(fit) pred = predict(fit, test, type = "response") # Preparing the required output format test <- read.csv("~/Downloads/test.csv") final = data.frame(ID = test$Id, Prediction = pred) colnames(final)[2] = "Prediction" write.csv(final, "tfi_rf.csv", row.names = F)
Those who do not remember the past are condemned to repeat it.George Santayana