



UNDERSTANDING THE PROBLEM
Trying my hand at Kaggle problems has given me a new dimension to ponder upon. You are forced to see the correlations between things you never imagined and forced to accelerate your mind power to brainstorm upon all possible options with a fixed set of data. After going through a few level zero problems and brushing through my R skills I tried my hand at a live competition. It took me a while to just figure out the problem statement and understand the data set for TalkingData Mobile User Demographics.
Kaggle link: click here
Problem Statement (trying to simplify it):
TalkingData is the largest third party platform which collects information from almost 70% of 500million mobile users in China. So, in this competition, we need to predict the age group of the mobile phone users using the data collect by TalkingData. Getting to know the age group of mobile users is very crucial for many companies as that helps them to do a very targeted marketing and present content accordingly.
Understanding the data:
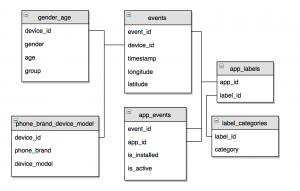

Keep the above image handy while attempting this problem, its a life saver.
The train set contains device ids, gender, age and demographical group.
The test set contains only the device ids.
- The type (brand, model) of mobile devices users use. phone_brand_device_model.csv
- When and where (the time and date, latitude and longitude) a user uses his/her mobile, corresponding to which an event id is created. So for example, every time you unlock your phone location and time is recorded by TalkingData and it is given an event id. events.csv
- Corresponding to each event id, all the installed apps in your phone and all the apps which are active is recorded (Each app has a unique app id). app_events.csv
- The category of the apps. app_labels.csv and label_categories.csv
Important Observations at first glance
- The data set for phone brands contain ALL the device ids in the train and test set. (Yeah!)
- Only 31% of device ids from train and test set are in the file events.csv and this also means we have only 31% devices whose app details are given. (This will make our task more difficult and we would need to choose a model which incorporates this)
- The device ids in test set can have brands and model numbers which are not present in the train set. (This means we have new factors in test which are not in train and our model also needs to consider this)
The above can be verified by using %in% in Rsum(train$device_id %in% events$device_id)
- Each device id can have more than one event id and each event id can have more than one app id and each app id can have more than one category.
Feature Engineering
- Number of apps in each event_id (for both active and installed apps)
- Time of the day when the device is most used. It may be that if the device is not being used much from 10am to 4pm he/she falls in the working age. Similarly, the teenagers may use it more at night.
- A correlation can also be found by checking if there is device who is using his/her device more during the weekends
- The number of events occurring each day. (maybe we can take the average of this)
- The location might play a role. But this would require some cleaning. There are a lot of (0,0) sets here which does not make much sense.
- Depending on the model we use, we can group the categories of the apps. This should play a vital role. For example, the young female would use more of the apps in the category fashion, photography.
Now let us visualize the data as much as possible and then try to develop a model to predict.
EXPLORATORY DATA ANALYTICS
Now, let’s visualize the data for TalkingData Mobile User Demographics we have and see if it really makes any sense and if we can get some more insights. (Not an expert at this, hopefully, these will be better in the future posts)
- Starting with the basic one, the histogram for gender in the train set. Here we can see that in our train set 70% are male and 30% female. Hence if we plot anything else wrt to gender, the male will be dominating.
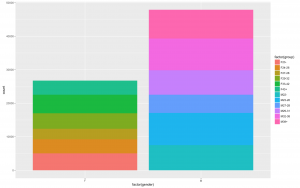
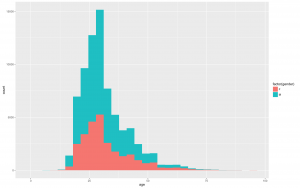
- Next, let’s look at the distribution of age in our train set.
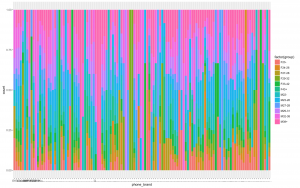
- Mobile brand and model number are going to be the deciding factor for our model, hence this graph between brand frequency and age group will be crucial. Here we the graphs is normalized so it will not give a good idea about the number, but luckily we can observe that there are a lot of brands which is gender and age specific.
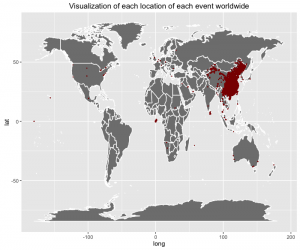
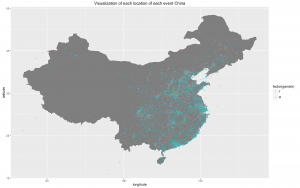
- Another thing to observe in the data is the location, i.e. latitude and longitude. There are a lot of cleaning to be done. One option is to replace the (0,0) with the mean corresponding to the device id. Also in the following world map, we can see that most of the points lie on land, which is good. And in the map of China, there are high clusters in the big cities. The map with the gender has very few data points compared to the other graph (only 30% of train)
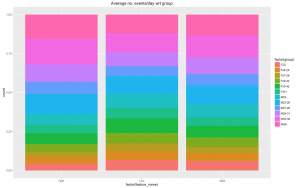
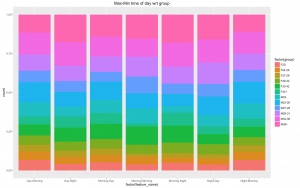
- Two other features we had thought about was the average number of events per day, and the most and least used times of the day. The graphs show the these do make an impact, so including these should improve our model.
- Tried to group the app categories, but grouping the categories and plotting it for the train (only 30% data available) does not show much improvement. So in our model, we should try to increase the groupings of the categories or include all the categories.








PREDICTING GENDER AND AGE
So one of our most important factor while building the model has to be mobile brand and model number and we would need to predict almost 70% devices using only this.
For TalkingData Mobile User Demographics problem, random Forest or regression would not be a good option to consider for this prediction, because of a large number of factors. RandomForest can take up to a maximum of 54 factors and any new level in the test would throw up an error. So one of the models to be considered is Gradient Boosting which is very helpful in cases of large factors (Use One-Hot Encoding ) and moreover, xgBoost is very fast. Initially, I had tried using it with only mobile brand and model, and obtaining a good result I added the other variables which further improved the score. Currently, the score is ~2.26544 and an accuracy of almost 96% being it the top 20% (not the final result).
Some handy functions
- %>% {dplyr}: Used for pipelining, can be very handy at times. Check an example below
- fread {data.table} : A very fast alternative to read.csv, but this creates a data table. It can be converted to a data frame using the above pipelining method
example % as.data.frame()
- library bit64: The device_id is in the format of integer64 for which this library is required but you we change that to character even while using fread using the parameter colClasses
- The following are used to get the means of age wrt category. So we will have a list of unique categories and the corresponding means of ages
tmp = as.data.frame(sapply(split(events$Day,events$device_id), mean))
tmp = data[,.(tmp = mean(age)), by=.(brand, model)]
- cut {base}: This is very useful to divide numeric values to factors if it is continuous. In our example, we can do it for latitude, longitude.
cut(location_new$longitude, breaks = c(-Inf, 80, 85, 90, Inf), labels = c("long1", "long2", "long3", "long4") right = FALSE) - grepl {dplyr} : Search for a pattern and return a logical value (grep returns index)
uni_appcat$cat = ifelse(grepl("gambillard|puzz|poker|sport|shoot|rpg", uni_appcat$category), "game", “Not_game”) - This replaces the values d1$phone_brand by adding phone_brand at the start
d1[,phone_brand:=paste0("phone_brand:",phone_brand)] - Also look at some basic functions like merge, unique, match (alternative: %in%), aggregate, paste, paste0, ifelse
Those who do not remember the past are condemned to repeat it.George Santayana